
Publications
You can also find my articles on my Google Scholar profile.
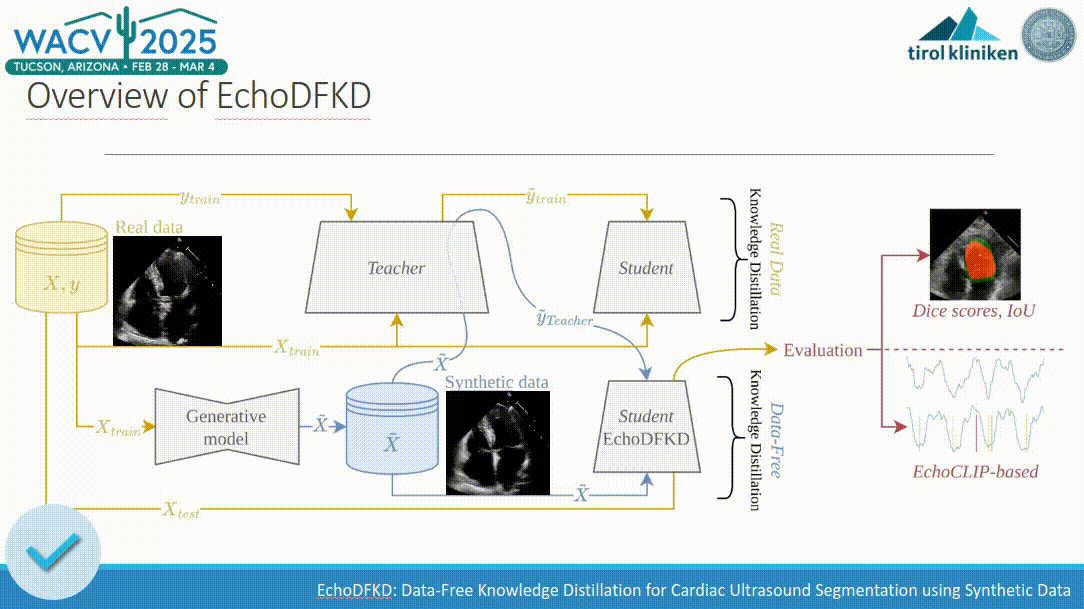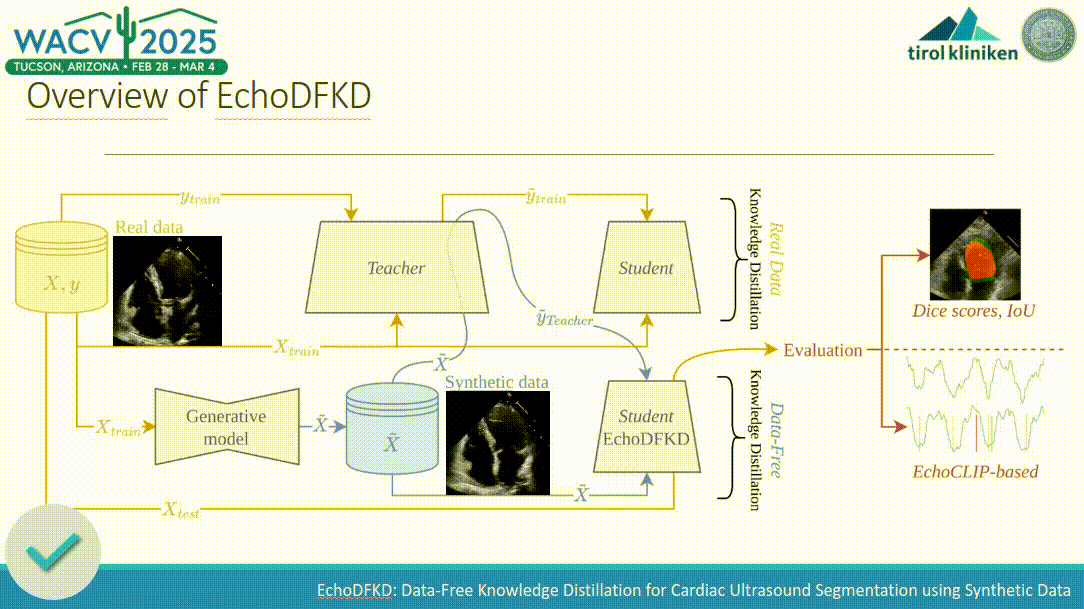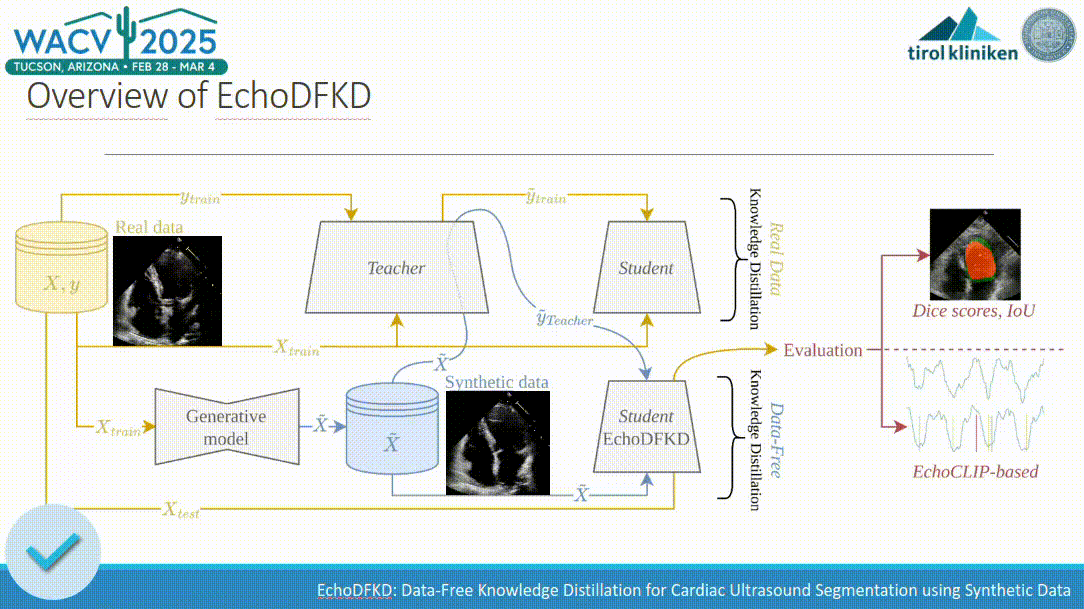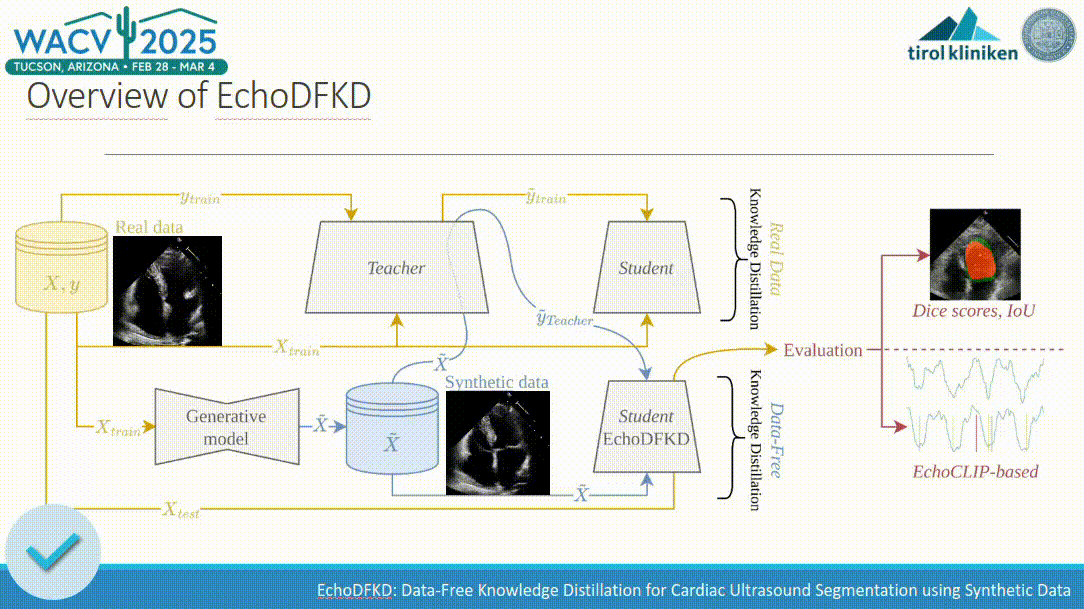
EchoDFKD: Data-Free Knowledge Distillation for Cardiac Ultrasound Segmentation using Synthetic Data
Grégoire Petit, Nathan Palluau, Axel Bauer, Clemens Dlaska
Exemplar-free class-incremental learning is very challenging due to the negative effect of catastrophic forgetting. The application of machine learning to medical ultrasound videos of the heart i.e. echocardiography has recently gained traction with the availability of large public datasets. Traditional supervised tasks such as ejection fraction regression are now making way for approaches focusing more on the latent structure of data distributions as well as generative methods. We propose a model trained exclusively by knowledge distillation either on real or synthetical data involving retrieving masks suggested by a teacher model. We achieve state-of-the-art (SOTA) values on the task of identifying end-diastolic and end-systolic frames. By training the model only on synthetic data it reaches segmentation capabilities close to the performance when trained on real data with a significantly reduced number of weights. A comparison with the 5 main existing methods shows that our method outperforms the others in most cases. We also present a new evaluation method that does not require human annotation and instead relies on a large auxiliary model. We show that this method produces scores consistent with those obtained from human annotations. Relying on the integrated knowledge from a vast amount of records this method overcomes certain inherent limitations of human annotator labeling.
@InProceedings{Petit_2025_WACV,
author = {Petit, Grégoire and Palluau, Nathan and Bauer, Axel and Dlaska, Clemens},
title = {EchoDFKD: Data-Free Knowledge Distillation for Cardiac Ultrasound Segmentation using Synthetic Data},
booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
month = {March},
year = {2025},
}Published in Winter Conference on Applications of Computer Vision (WACV), 2025
In Deep Learning applied to computer vision, one critical task is segmentation, which is essential for accurately interpreting and analyzing visual data. However, segmentation as an annotation task is often resource-intensive and time-consuming, particularly in the medical domain. Knowledge distillation (KD) typically aims to transfer knowledge, such as the ability to segment data, from a large, complex model (often referred to as the teacher model) to a smaller, more efficient model (the student model). This process involves training the student model to replicate the outputs of the teacher model on certain tasks. By doing so, the student model inherits the teacher’s capabilities relevant to this task, requiring fewer computational resources. Beyond model compression, KD has demonstrated its versatility in various applications, such as adversarial robustness, ensemble fusion, continual learning, partial or missing labels, multi-task learning, and cross-modal learning.
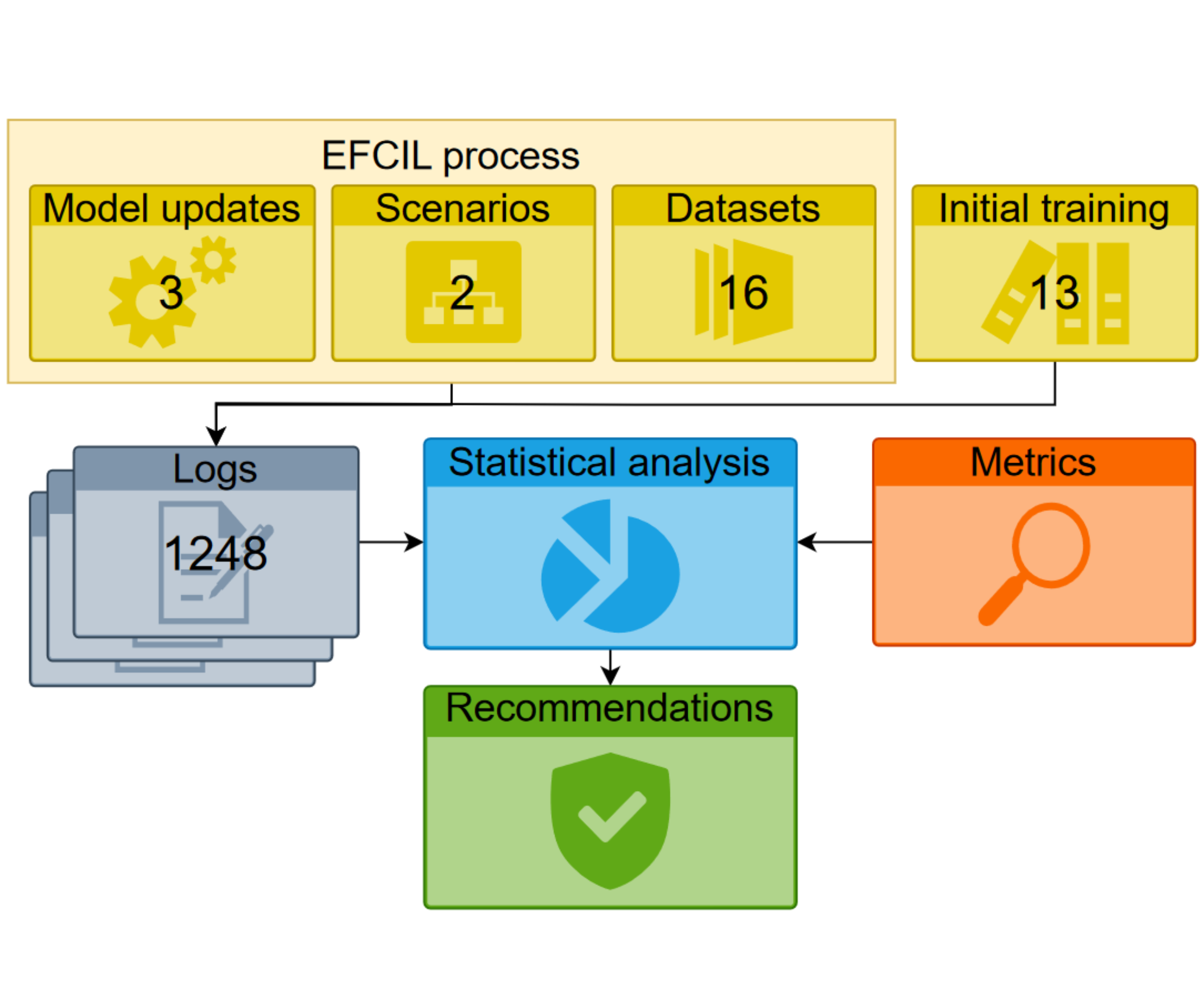
An Analysis of Initial Training Strategies for Exemplar-Free Class-Incremental Learning
Grégoire Petit, Michael Soumm, Eva Feillet, Adrian Popescu, Bertrand Delezoide, David Picard and Céline Hudelot
Class-Incremental Learning (CIL) aims to build classification models from data streams. At each step of the CIL process, new classes must be integrated into the model. Due to catastrophic forgetting, CIL is particularly challenging when examples from past classes cannot be stored, the case on which we focus here. To date, most approaches are based exclusively on the target dataset of the CIL process. However, the use of models pre-trained in a self-supervised way on large amounts of data has recently gained momentum. The initial model of the CIL process may only use the first batch of the target dataset, or also use pre-trained weights obtained on an auxiliary dataset. The choice between these two initial learning strategies can significantly influence the performance of the incremental learning model, but has not yet been studied in depth. Performance is also influenced by the choice of the CIL algorithm, the neural architecture, the nature of the target task, the distribution of classes in the stream and the number of examples available for learning. We conduct a comprehensive experimental study to assess the roles of these factors. We present a statistical analysis framework that quantifies the relative contribution of each factor to incremental performance. Our main finding is that the initial training strategy is the dominant factor influencing the average incremental accuracy, but that the choice of CIL algorithm is more important in preventing forgetting. Based on this analysis, we propose practical recommendations for choosing the right initial training strategy for a given incremental learning use case. These recommendations are intended to facilitate the practical deployment of incremental learning.
@article{petit2023analysis,
title={An Analysis of Initial Training Strategies for Exemplar-Free Class-Incremental Learning},
author={Petit, Grégoire and Soumm, Michael and Feillet, Eva and Popescu, Adrian and Delezoide, Bertrand and Picard, David and Hudelot, Céline},
journal={arXiv preprint arXiv:2308.11677},
year={2023}
}Published in Winter Conference on Applications of Computer Vision (WACV), 2024
Real-world applications of machine learning (ML) often involve training models from data streams characterized by distributional changes and limited access to past data. This scenario presents a challenge for standard ML algorithms, as they assume that all training data is available at once. Continual learning addresses this challenge by building models designed to incorporate new data while preserving previous knowledge. Class-incremental learning (CIL) is a type of continual learning that handles the case where the data stream is made up of batches of classes. It is particularly challenging in the exemplar-free case (EFCIL), i.e. when storing examples of previous classes is impossible due to memory or confidentiality constraints. CIL algorithms must find a balance between knowledge retention, i.e. stability, and adaptation to new information, i.e. plasticity. Many existing EFCIL methods update the model at each incremental step using supervised fine-tuning combined with a distillation loss, and thus tend to favor plasticity over stability. Another line of work freezes the initial model and only updates the classifier. This approach has recently gained interest due to the availability of models pre-trained on large external datasets, often through self-supervision. While pre-trained models provide diverse and generic features, there are limits to their transferability, and these limits have not been studied in depth in the context of EFCIL.
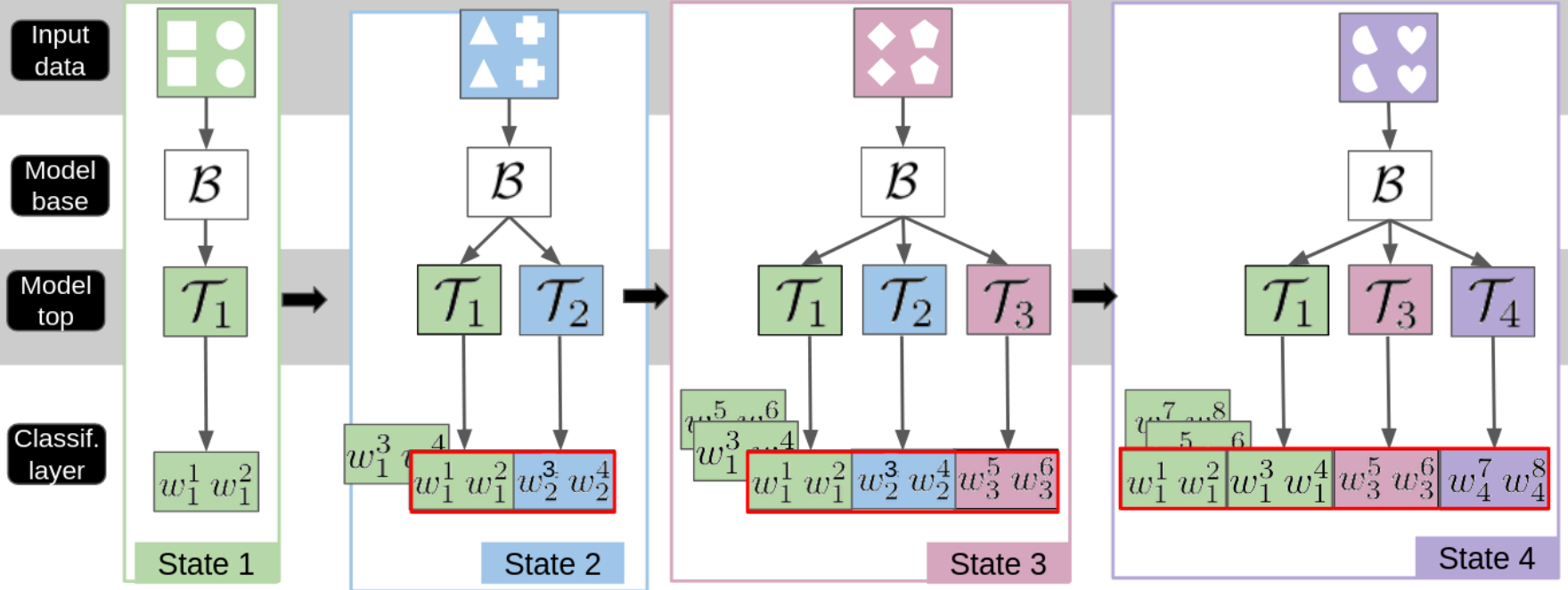
PlaStIL: Plastic and Stable Memory-Free Class-Incremental Learning
Grégoire Petit, Adrian Popescu, Eden Belouadah, David Picard and Bertrand Delezoide
Plasticity and stability are needed in class-incremental learning in order to learn from new data while preserving past knowledge. Due to catastrophic forgetting, finding a compromise between these two properties is particularly challenging when no memory buffer is available. Mainstream methods need to store two deep models since they integrate new classes using fine tuning with knowledge distillation from the previous incremental state. We propose a method which has similar number of parameters but distributes them differently in order to find a better balance between plasticity and stability. Following an approach already deployed by transfer-based incremental methods, we freeze the feature extractor after the initial state. Classes in the oldest incremental states are trained with this frozen extractor to ensure stability. Recent classes are predicted using partially fine-tuned models in order to introduce plasticity. Our proposed plasticity layer can be incorporated to any transfer-based method designed for memory-free incremental learning, and we apply it to two such methods. Evaluation is done with three large-scale datasets. Results show that performance gains are obtained in all tested configurations compared to existing methods.
@article{petit2023plastil,
Title = {PlaStIL: Plastic and Stable Memory-Free Class-Incremental Learning},
Author = {G. Petit, A. Popescu, E. Belouadah, D. Picard, B. Delezoide},
Journal = {Second Conference on Lifelong Learning Agents},
Year = {2022}
}Published in Second Conference on Lifelong Learning Agents, 2023
Class-incremental learning (CIL) enables the adaptation of artificial agents to dynamic environments in which data occur sequentially. CIL is particularly useful when the training process is performed under memory and/or computational constraints. However, it is really susceptible to catastrophic forgetting, which refers to the tendency to forget past information when learning new data. Most recent CIL methods use fine-tuning with knowledge distillation from the previous model to preserve past information. Knowledge distillation has been progressively refined to improve CIL performance. An alternative approach to CIL is inspired by transfer learning. These methods use a feature extractor which is frozen after the initial CIL state. They become competitive in exemplar-free CIL, a difficult setting due to a strong effect of catastrophic forgetting. The main challenge is to find a good plasticity-stability balance because fine-tuning methods favor plasticity, while transfer-based methods only address stability.
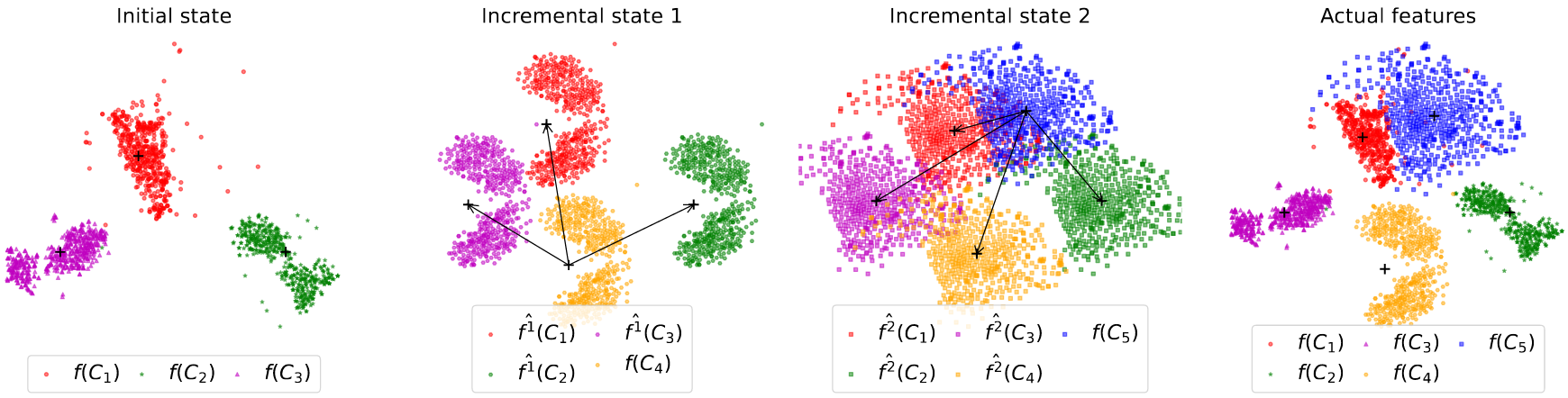
FeTrIL: Feature Translation for Exemplar-Free Class-Incremental Learning
Grégoire Petit, Adrian Popescu, Hugo Schindler, David Picard and Bertrand Delezoide
Exemplar-free class-incremental learning is very challenging due to the negative effect of catastrophic forgetting. A balance between stability and plasticity of the incremental process is needed in order to obtain good accuracy for past as well as new classes. Existing exemplar-free class-incremental methods focus either on successive fine tuning of the model, thus favoring plasticity, or on using a feature extractor fixed after the initial incremental state, thus favoring stability. We introduce a method which combines a fixed feature extractor and a pseudo-features generator to improve the stability-plasticity balance. The generator uses a simple yet effective geometric translation of new class features to create representations of past classes, made of pseudo-features. The translation of features only requires the storage of the centroid representations of past classes to produce their pseudo-features. Actual features of new classes and pseudo-features of past classes are fed into a linear classifier which is trained incrementally to discriminate between all classes. The incremental process is much faster with the proposed method compared to mainstream ones which update the entire deep model. Experiments are performed with three challenging datasets, and different incremental settings. A comparison with ten existing methods shows that our method outperforms the others in most cases.
@InProceedings{Petit_2023_WACV,
author = {Petit, Grégoire and Popescu, Adrian and Schindler, Hugo and Picard, David and Delezoide, Bertrand},
title = {FeTrIL: Feature Translation for Exemplar-Free Class-Incremental Learning},
booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
month = {January},
year = {2023},
pages = {3911-3920}
}Published in Winter Conference on Applications of Computer Vision (WACV), 2023
Deep learning has dramatically improved the quality of automatic visual recognition, both in terms of accuracy and scale. Current models discriminate between thousands of classes with an accuracy often close to that of human recognition, assuming that sufficient training examples are provided. Unlike humans, algorithms reach optimal performance only if trained with all data at once whenever new classes are learned. This is an important limitation because data often occur in sequences and their storage is costly. Also, iterative retraining to integrate new data is computationally costly and difficult in time- or computation-constrained applications Incremental learning was introduced to reduce the memory and computational costs of machine learning algorithms. The main problem faced by class-incremental learning (CIL) methods is catastrophic forgetting, the tendency of neural nets to underfit past classes when ingesting new data. Many recent solutions, based on deep nets, use replay from a bounded memory of the past to reduce forgetting. However, replay-based methods make a strong assumption because past data are often unavailable. Also, the footprint of the image memory can be problematic for memory-constrained devices. Exemplar-free class-incremental learning (EFCIL) methods recently gained momentum. Most of them use distillation to preserve past knowledge, and generally favor plasticity. New classes are well predicted since models are learned with all new data and only a representation of past data. A few EFCIL methods are inspired by transfer learning. They learn a feature extractor in the initial state, and use it as such later to train new classifiers. In this case, stability is favored over plasticity since the model is frozen.
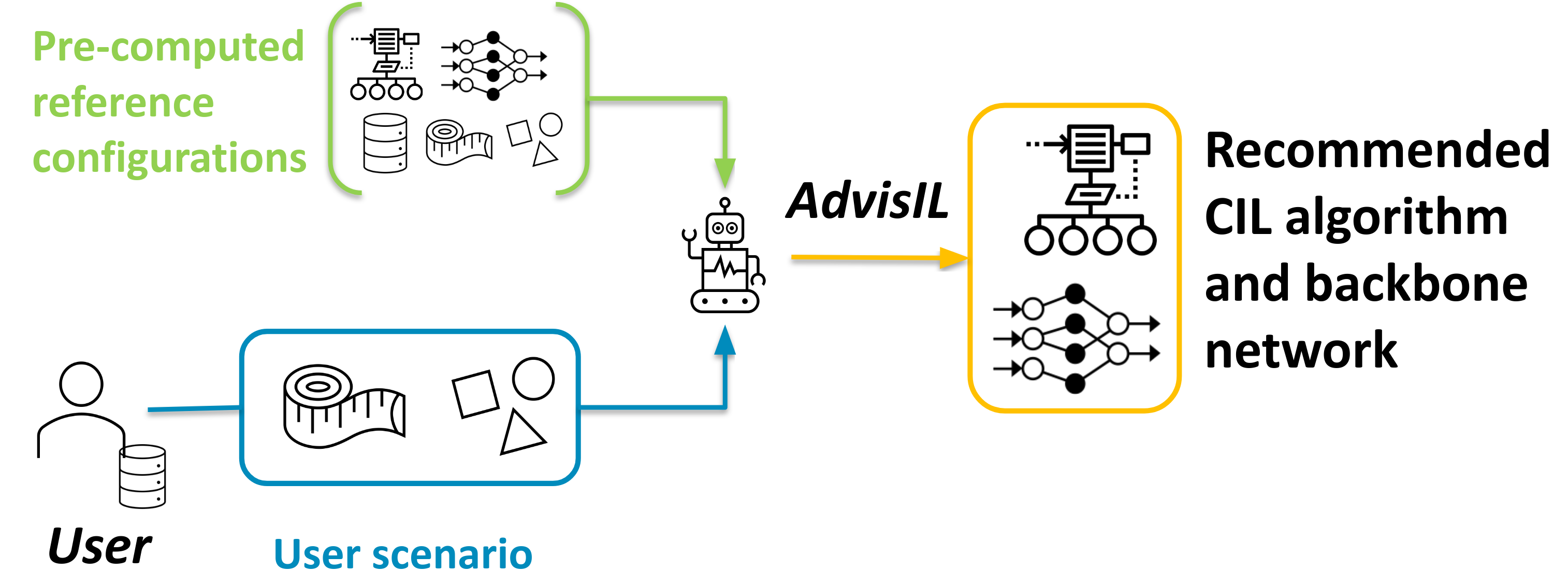
AdvisIL: A Class-Incremental Learning Advisor
Eva Feillet, Grégoire Petit, Adrian Popescu, Marina Reyboz and Céline Hudelot
Recent class-incremental learning methods combine deep neural architectures and learning algorithms to handle streaming data under memory and computational constraints. The performance of existing methods varies depending on the characteristics of the incremental process. To date, there is no other approach than to test all pairs of learning algorithms and neural architectures on the training data available at the start of the learning process to select a suited algorithm-architecture combination. To tackle this problem, in this article, we introduce AdvisIL, a method which takes as input the main characteristics of the incremental process (memory budget for the deep model, initial number of classes, size of incremental steps) and recommends an adapted pair of learning algorithm and neural architecture. The recommendation is based on a similarity between the user-provided settings and a large set of pre-computed experiments. AdvisIL makes class-incremental learning easier, since users do not need to run cumbersome experiments to design their system. We evaluate our method on four datasets under six incremental settings and three deep model sizes. We compare six algorithms and three deep neural architectures. Results show that AdvisIL has better overall performance than any of the individual combinations of a learning algorithm and a neural architecture. AdvisIL's code is available at https://github.com/EvaJF/AdvisIL.
@InProceedings{Feillet_2023_WACV,
author = {Feillet, Eva and Petit, Grégoire and Popescu, Adrian and Reyboz, Marina and Hudelot, Céline},
title = {AdvisIL - A Class-Incremental Learning Advisor},
booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
month = {January},
year = {2023},
pages = {2400-2409}
}Published in Winter Conference on Applications of Computer Vision (WACV), 2023